How to run Spark SQL queries on encrypted data
TL;DR: We are excited to present Opaque SQL, an open-source platform for securely running Spark SQL queries on encrypted data-in-use. Originally built by top systems and security researchers at UC Berkeley, the platform uses hardware enclaves to securely execute queries on private data in an untrusted environment. Opaque SQL partitions the codebase into trusted and untrusted sections to improve runtime and reduce the amount of code that needs to be trusted. The project was designed to introduce as little changes to the Spark API as possible; any user familiar with Spark SQL should have no trouble running secure queries with Opaque SQL.
What is Spark SQL?
Apache Spark is a popular distributed computing framework used by data teams worldwide for processing large batches of data. One of its modules, Spark SQL, allows users to interact with structured, tabular data. This can be done through a DataSet/DataFrame API available in Scala or Python, or by using standard SQL queries. Spark SQL’s guide dives in deeper, but you can see a quick example of both below:
Spark components
For its distributed computing architecture, Spark adopts a master-worker architecture where the master is known as the driver and workers are known as executors.
The driver is the process where the main Spark program runs. It is responsible for translating a user’s code into jobs to be run on the executors. For example, given a SQL query, the driver builds the SQL plan, performs optimization, and resolves the physical operators that the execution engine will use. It then schedules the compute tasks among the workers and keeps track of their progress until completion. Any metadata, such as the number of data partitions to use or how much memory each worker should have, is set on the driver.
The executors are responsible for the actual computation. Given a task from the driver, an executor performs the computation and coordinates its progress with the driver. They are launched at the start of every Spark application and can be dynamically removed and added by the driver as needed.
Computing on encrypted data using MC²
The MC² Project is a collection of tools for secure multi-party collaboration and coopetition (MC²). This goal is achieved through the use of hardware enclaves. Enclaves provide strong security guarantees, most notably keeping data encrypted in memory while in use. They also provide remote attestation, which ensures that the enclaves responsible for computation are running the correct sets of instructions.
The result is a platform capable of computing on sensitive data in an untrusted environment, such as a public cloud. For a more detailed explanation of the project and its use cases, see our introductory blog post.
Putting it together: Opaque SQL

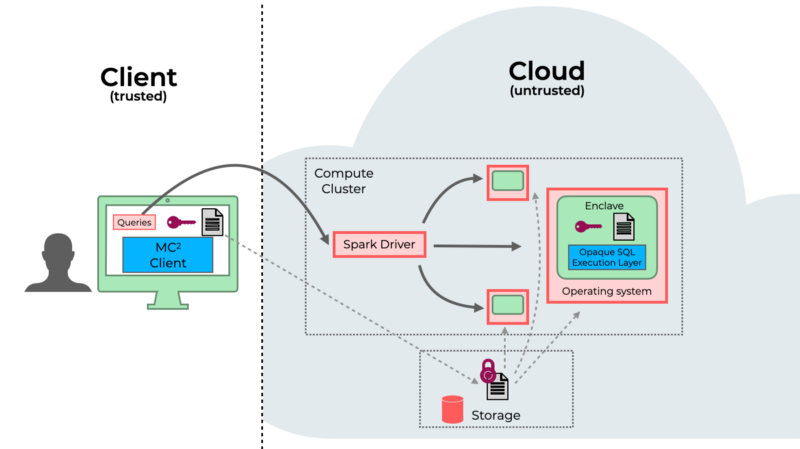
At a high level, Opaque SQL is a Spark package that uses hardware enclaves to partition Spark’s architecture into untrusted and trusted components. It was originally developed at UC Berkeley’s RISELab as the implementation of an NSDI 2017 paper.
The driver is untrusted: While the query and table schemas are not hidden because the Spark driver still needs to perform planning, the driver is only able to access completely encrypted data. The physical plan built will contain entirely encrypted operators in place of vanilla Spark operators. (However, since the driver is building the plan, the client needs to verify that the plan created is correct; support for this is currently a work-in-progress and will be part of the next release.)
The executor machines contain trusted enclaves where computation is performed: During execution, the executor program calls into Opaque SQL’s native library that’s loaded inside the hardware enclave. The native library provides encrypted SQL operators that can execute on encrypted, sensitive data inside the enclave. Any private column data such as SSNs, bank account numbers, or PHI remains encrypted in memory and is protected by the enclave.
A key benefit of partitioning is that most of Spark does not need to run inside enclaves. Components that are difficult to port or have slow performance inside an enclave, such as networking, planning, or scheduling, can reside outside. Partitioning also improves security by reducing the trusted computing base, i.e., the amount of code that runs within the enclave and therefore needs to be vetted beforehand.
The entry-point to Opaque SQL: The MC² Client
The MC² Client is responsible for communicating with the Spark driver and performing remote attestation and query submission. It is a trusted component that is located on the user’s machine.
Remote attestation involves having the user verify that the enclaves were initialized correctly with the right code to run. The client talks to the driver, who forwards attestation information to the enclaves that are running on the executors. No enclave is able to decrypt any data until attestation is complete and the results are verified by the user. Even though the driver is handling communication, no information sent allows the untrusted portion of the program to “cheat” and learn anything it shouldn’t.
Query submission happens after attestation is completed successfully, and is the step where Spark code is remotely submitted to the driver for evaluation. Any intermediate values remain encrypted throughout the lifetime of the execution stage.
For more information about the MC² Client and for an introduction to a Docker quickstart, visit the project’s README.
Usage of the Spark SQL query
A key design for Opaque SQL is to have our API as similar to Spark SQL as possible. An encrypted DataFrame is loaded in through a special format:
After loading, Spark transformations are applied exactly the same as vanilla Spark, only with new encrypted physical operators being created during planning:
To save the result after a query has been created, use the same format as loading:
For a more comprehensive list of supported functionalities, visit our functionality documentation.
Conclusion
Opaque SQL enables analytics processing over encrypted DataFrames, with little overhead to vanilla Spark. In turn, this extension protects data-in-use in the cloud as well as at rest. Queries are submitted remotely with the help of the MC² Client, an easy-to-use interface for communicating with all compute services on the MC² stack.
For more blog posts on how to securely process data with the MC² Project, visit our resources page. We would love your contributions and support! Please check out the Github repo to see how you can contribute.
Thanks to Ben Huberman and pancy