
New techniques in analytics and machine learning offer the ability to process ever-increasing amounts of data, but access to such data has lagged far behind the technological advances in data processing. High-value data is often split across multiple organizations and access to it is encumbered by business competition and regulatory constraints. For example, banks wish to detect illegal money laundering activities by analyzing their joint customer transaction data, but they are unwilling to share this data with competitors.
There are two major paradigms for addressing this problem: federated learning and secure learning. The former was first introduced in 2016 by McMahan et al. [1], who coined the term for platforms that support solving a learning task “by a loose federation of participating devices which are coordinated by a central server.” This line of research has since garnered significant interest from both academia and industry, especially in the machine learning community, but has also received attention from the security community. On the other hand, the idea of secure collaborative learning (referred to as secure learning for the rest of the blog) is also used to refer to collaboratively computing a task on data generated from distinct parties. In this paradigm, there is a special focus on enabling generic computation capabilities among mutually distrusting parties without leveraging a trusted third party or revealing any party’s private input to any entity.
At this point, you might wonder what, if any, are the differences between federated and secure learning. After all, the goals seem very similar: collaboratively compute a learning task across multiple parties. In this blog post, we will shed some light on the major differences between these two techniques.
Setup
When the term was first introduced, federated learning targeted computing on data collected from mobile and edge devices, often with the help of a trusted central server that aggregates plaintext gradient updates. On the other hand, much of the secure learning effort has focused on collaborating among multiple institutions, without a trusted central server that sees intermediate plaintext information.
We define a “participant” as a party (a mobile device, a bank) who contributes data to the training process. The following are common setups for the two paradigms:
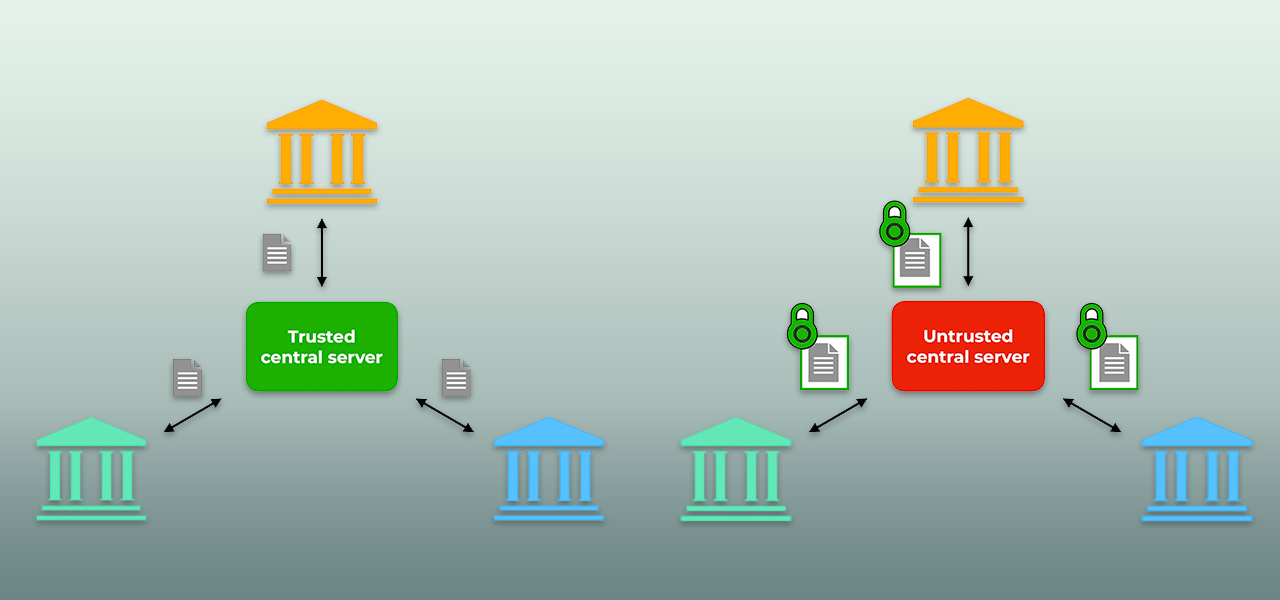
- Federated learning: Many small participants train a model under the coordination of a trusted central server. This central server might be hosted by a large company like Google/Apple that is also involved in the training process, or a neutral third party entity:

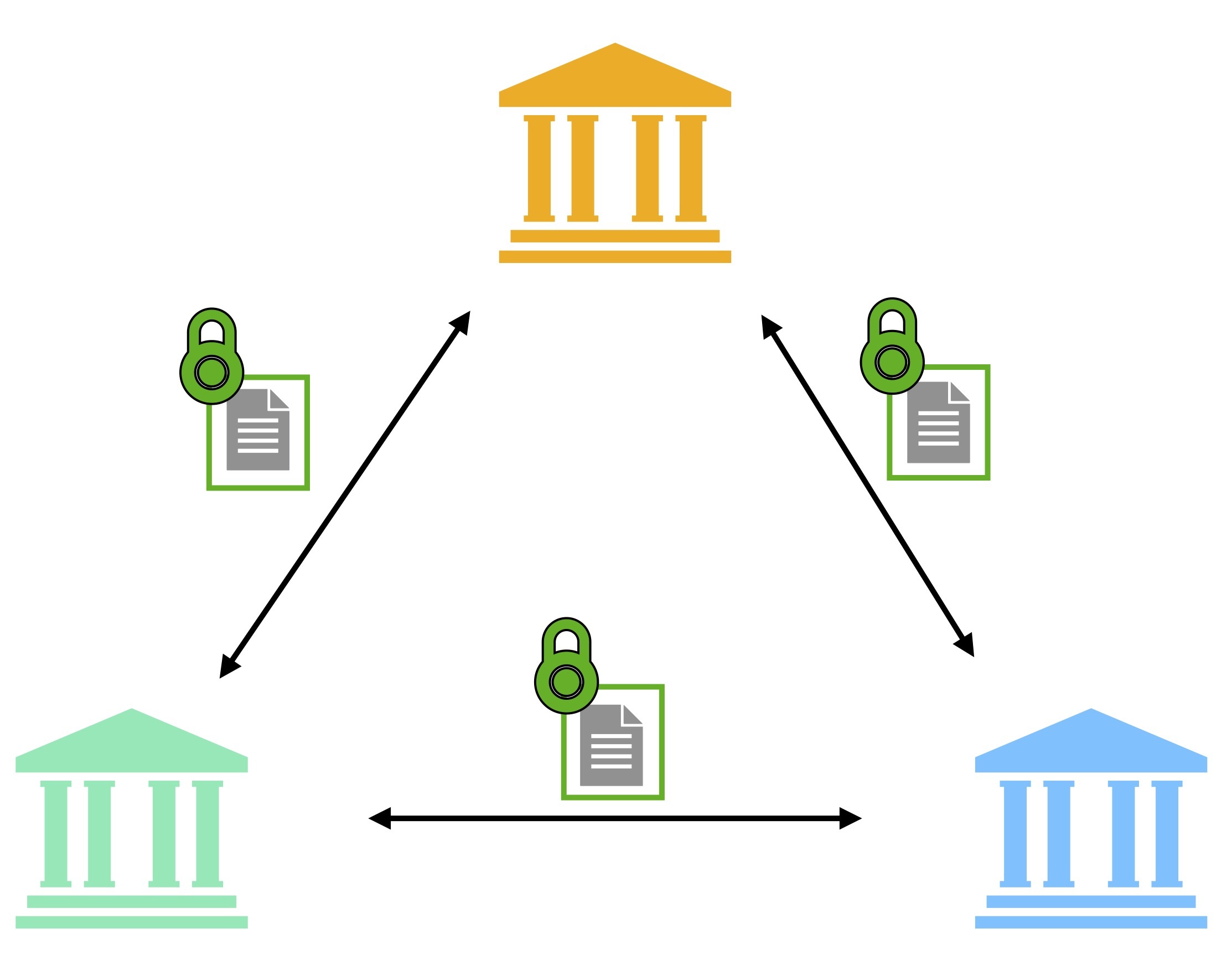
- Secure learning: Fewer participants with larger datasets (e.g., banks, hospitals) train a model with no trusted central server. Based on the technique used, the training can leverage an untrusted orchestrator or be fully decentralized:




Workflow
Below is a typical federated training workflow taken from a survey paper, which shows a single iteration of the training process:
- Participant selection: the central server (e.g., a server hosted by Google/Apple) chooses a set of participants
- Broadcast: the selected participants download the current model and a training program
- Local computation: each participant computes a model update using its local data and the training program
- Aggregation: the server collects and aggregates the individual updates
- Model update: the server updates the model using the aggregated update
There are two major techniques used in secure learning, trusted execution environments (TEEs, also known as enclaves) and advanced cryptography, and each has its own training workflow.
- TEEs:
- TEEs are created on an orchestrator and the machine learning platform code is loaded into each TEE (note that the central server is not trusted)
- Participants use remote attestation to verify that the correct code has been loaded within TEEs and establish encrypted connections to the TEEs
- Participants transfer their private data to the TEEs via encrypted connections
- Training is initiated within TEEs
- Advance cryptography: There are different cryptographic techniques that can be utilized, such as MPC and fully homomorphic encryption (FHE).
- In the MPC setting, participants usually perform the computation on encrypted/randomized data without a central server. The participants exchange encrypted messages with each other and execute encrypted training to emulate a fully trusted central server.
- FHE, on the other hand, allows participants to encrypt their data once and outsource the computation to an untrusted server.
As you can see, federated learning and secure learning have very different training workflows. Moreover, training is usually only one component of the machine learning lifecycle; the resulting model also needs to be released to the appropriate parties, then tested and deployed in an application. Federated learning often assumes that the central server is the one who receives the final model. For example, Google utilizes federated learning in Gboard mobile keyboard [2, 3], and Apple uses it for iOS [4]. Secure learning, on the other hand, usually releases the resulting model to each of the participants directly. For example, multiple banks collaborating on an anti-money laundering model will each receive the final model, and may further fine-tune the model and deploy a customized version. Since the post-training processing is usually done by individual parties without collaboration, we will mainly analyze the properties of the collaborative training process in the rest of this post.
Security
When it comes to the threat model, federated learning and secure learning put different amounts of trust in the different parties described above.
In the most basic version of federated learning, the central server is fully trusted: it collects and aggregates the participants’ model updates, so it also sees the participants’ updates in plaintext. Both the server and the participants are trusted to follow the protocol. There have been follow up designs aimed at improving confidentiality and integrity of the base federated learning scheme. Some popular directions are:
- Improve the participants’ privacy leakage at the central server by using techniques such as secure aggregation [5], local differential privacy [6]
- Protect against model poisoning from malicious participants by using techniques such as enforcing a norm constraint [7]
On the other hand, secure learning systems often utilize techniques such as hardware TEEs and secure multiparty computation. The goal is to create a real world execution environment that has the same security guarantees as an ideal world execution environment where the parties are offloading the compute to a trusted third party. Of course, this is only an “emulation”; in reality, no trusted third party server is utilized!
This means that none of the parties sees any intermediate output, e.g., any individual or aggregated model updates. Any party who should learn the final model will see it, but otherwise does not learn any extra information. In the strongest setting, the parties can be potentially malicious and do not follow the protocol.
Federated learning designs often have weaker security guarantees compared to secure learning designs. In the basic federated learning design, the central server sees individual model updates, which embeds important information about each participant’s data. Secure aggregation for federated learning still assumes that the central server sees per-round aggregated updates, which are intermediate outputs that can leak information. Additionally, since the participants must generate new model updates, they also see the per-round aggregated updates. In terms of integrity, Techniques for protecting against model poisoning are also often heuristics. Secure learning, on the other hand, has a well-defined threat model and can protect against both privacy and integrity attacks during training. As mentioned in the previous paragraph, none of the parties sees any intermediate output. Integrity is also guaranteed when the secure learning protocol handles malicious parties: the protocol ensures that, once the execution has started, it will execute correctly on a particular set of inputs. These inputs cannot be changed once the computation begins.
One final word of caution: both federated learning and secure learning suffer from input data poisoning attacks (malicious participants may contribute bad/fake data) and output privacy leakage attacks (the final model may reveal too much information about the parties’ private inputs). These are inherently possible even in the secure learning setting since participants must be allowed to choose their own inputs, and participants also need to learn the final output. Addressing these problems will require machine learning insights and the appropriate incentive mechanisms.
Performance
While secure learning has stronger security guarantees, federated learning designs could execute much faster and tend to scale well to millions of participants. It has better bandwidth savings and can easily deal with updated data since only small updates need to be sent to the central server. Additionally, compute is fast since many designs assume that all computation is executed on plaintext data.
Secure learning’s performance can vary based on the techniques utilized. Our previous blog post presented detailed performance overheads, which can range from 20% for TEEs to multiple orders of magnitude overhead in FHE/MPC-based training.
Conclusion
Federated learning and secure learning are two different paradigms for collaboratively training on data from multiple parties. For a given application, we recommend that you analyze setup, security, and performance requirements in order to decide which paradigm makes sense. As a general rule of thumb, we believe that you should choose secure learning over federated learning when:
- You care deeply about the privacy of your data
- There are relatively few data contributors (10 – 100s) who also wish to deploy the final model
- You want to achieve the same model accuracy as a fully centralized setting, i.e., training within a datacenter
References
[1] McMahan, Brendan, et al. “Communication-efficient learning of deep networks from decentralized data.” Artificial intelligence and statistics. PMLR, 2017.
[2] Sundar Pichai. Google’s Sundar Pichai: Privacy Should Not Be a Luxury Good. New York Times, May 7, 2019.
[3] Timothy Yang, Galen Andrew, Hubert Eichner, Haicheng Sun, Wei Li, Nicholas Kong, Daniel Ramage, and Françoise Beaufays. Applied federated learning: Improving Google keyboard query suggestions. arXiv preprint 1812.02903, 2018.
[4] Apple. Private Federated Learning (NeurIPS 2019 Expo Talk Abstract). https://nips.cc/ExpoConferences/2019/schedule?talk_id=40, 2019.
[5] Bonawitz, Keith, et al. “Practical secure aggregation for privacy-preserving machine learning.” proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. 2017.
[6] Shiva Prasad Kasiviswanathan, Homin K. Lee, Kobbi Nissim, Sofya Raskhodnikova, and Adam D. Smith. What can we learn privately? SIAM J. Comput., 40(3):793–826, 2011. URL https://doi.org/10. 1137/090756090.
[7] Ziteng Sun, Peter Kairouz, Ananda Theertha Suresh, and H Brendan McMahan. Can you really backdoor federated learning? arXiv preprint arXiv:1911.07963, 2019.